Hadoop自升级到2.x版本之后,有很多属性的名称已经被遗弃了,虽然这些被遗弃的属性名称目前还可以用,但是这里还是建议用新的属性名,主要遗弃的属性名称主要见下面表格:已经被遗弃属性的名称新的属性名称create.empty.dir.if.nonexistmapreduce.jobcontrol.createdir.ifnotexistdfs.access.time.precisiondfs.namenode.accesstime.prec w397090770 11年前 (2014-02-13) 17374℃ 0评论10喜欢
在本博客的《Spark 0.9.1 Standalone模式分布式部署》详细的介绍了如何部署Spark Standalone的分布式,在那篇文章中并没有介绍如何来如何来测试,今天我就来介绍如何用Java来编写简单的程序,并在Standalone模式下运行。 程序的名称为SimpleApp.java,通过调用Spark提供的API进行的,在程序编写前现在pom引入相应的jar依赖:[code lang="JA w397090770 11年前 (2014-04-24) 7632℃ 0评论2喜欢
本博客前两篇文章介绍了如何在脚本中使用Scala(《在脚本中运行Scala》、《在脚本中使用Scala的高级特性》),我们可以在脚本里面使用Scala强大的语法,但细心的同学可能会发现每次运行脚本的时候会花上一大部分时间,然后才会有结果。我们来测试下面简单的Scala脚本:[code lang="shell"]#!/bin/shexec scala "$0" "$@" w397090770 9年前 (2015-12-17) 4742℃ 0评论8喜欢
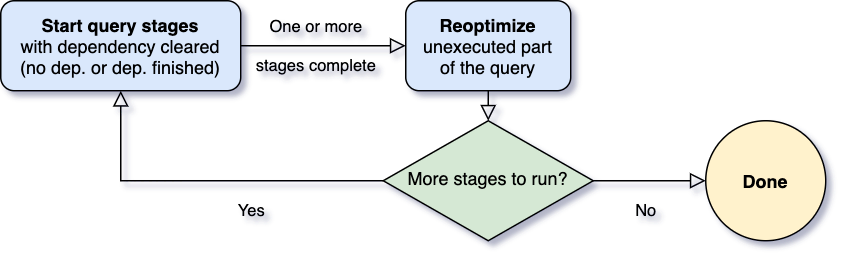
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 4年前 (2020-05-30) 1703℃ 0评论4喜欢
有一种非常常见的场景那就是使用其他数据库作为主要的数据存储,而Elasticsearch用来检索数据。这也意味着主数据库发生的一切变更都需要将其拷贝到Elasticsearch中。如果这时候有多个进程负责数据的同步,就会遇到《Elasticsearch乐观锁并发控制(optimistic concurrency control)》文章中提到的并发问题。 如果你的主数据库已经有 w397090770 8年前 (2016-08-12) 1653℃ 0评论0喜欢
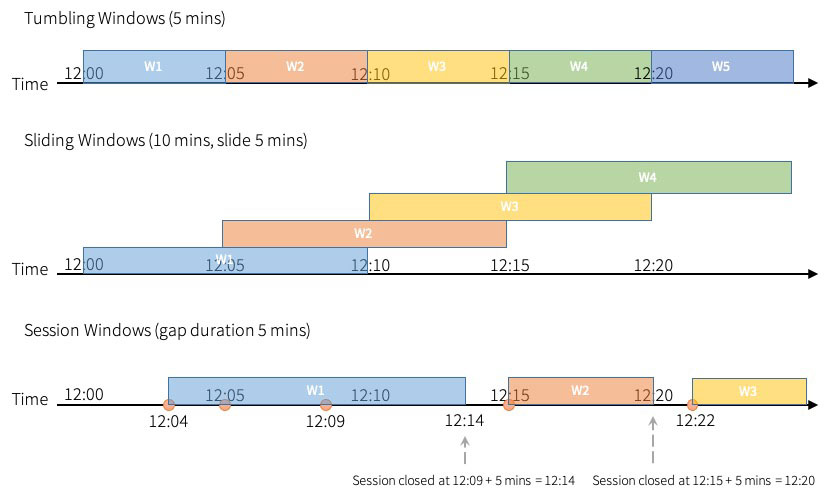
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had w397090770 3年前 (2021-10-21) 813℃ 0评论0喜欢
一、概述有时候我们需要设计这样一种数据结构:它能快速在要求位置插入或者删除一段数据。先考虑两种简单的数据结构:数组和链表。数组的优点是能够在O(1)的时间内找到所要执行操作的位置,但其缺点是无论是插入或删除都要移动之后的所有数据,复杂度是O(n)的。链表优点是能够在O(1)的时间内插入和删除一段数据,但缺点 w397090770 12年前 (2013-04-03) 5830℃ 0评论7喜欢
在Wordpress后台的设置->阅读->博客页面至多显示里面可以设置每页最多显示的文章数目,但是那个设置只能将所有的类别(首页、分类目录页、标签页、作者页)显示的文章数都设置成一个值。 但是在开发Wordpress主题的时候,有些需求需要修改不同类别的每页显示的文章数。比如首页显示10篇;分类页显示20篇;标签页显示3 w397090770 10年前 (2014-11-30) 6246℃ 0评论7喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 4年前 (2020-05-14) 2222℃ 0评论4喜欢
在这篇文章中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建JSON数据变得非常地简单。随着WEB和手机应用的流行,JSON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事实上的标准格式了。但是使用现有的工具,用户常常需要开发出复杂的程序 w397090770 10年前 (2015-02-04) 14334℃ 1评论16喜欢
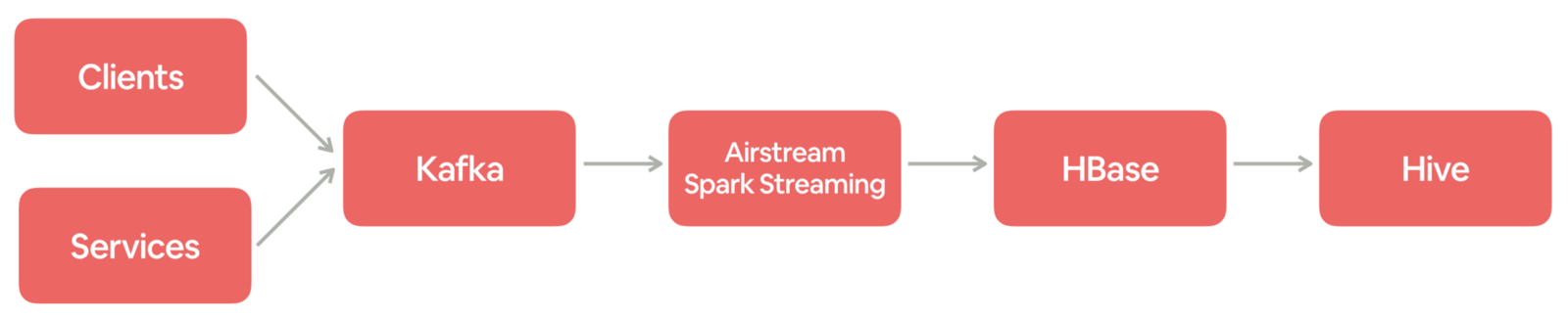
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 5年前 (2019-05-19) 2860℃ 0评论8喜欢
在 Spark 或 Hive 中,我们可以使用 LATERAL VIEW + EXPLODE 或 POSEXPLODE 将 array 或者 map 里面的数据由行转成列,这个操作在数据分析里面很常见。比如我们有以下表:[code lang="sql"]CREATE TABLE `default`.`iteblog_explode` ( `id` INT, `items` ARRAY<STRING>)[/code]表里面的数据如下:[code lang="sql"]spark-sql> SELECT * FROM iteblog_explode;1 ["iteblog.co w397090770 2年前 (2022-08-08) 1905℃ 0评论7喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 w397090770 9年前 (2015-09-09) 7374℃ 0评论5喜欢
下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 10年前 (2014-12-29) 16576℃ 0评论5喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 5年前 (2019-09-10) 2186℃ 0评论2喜欢
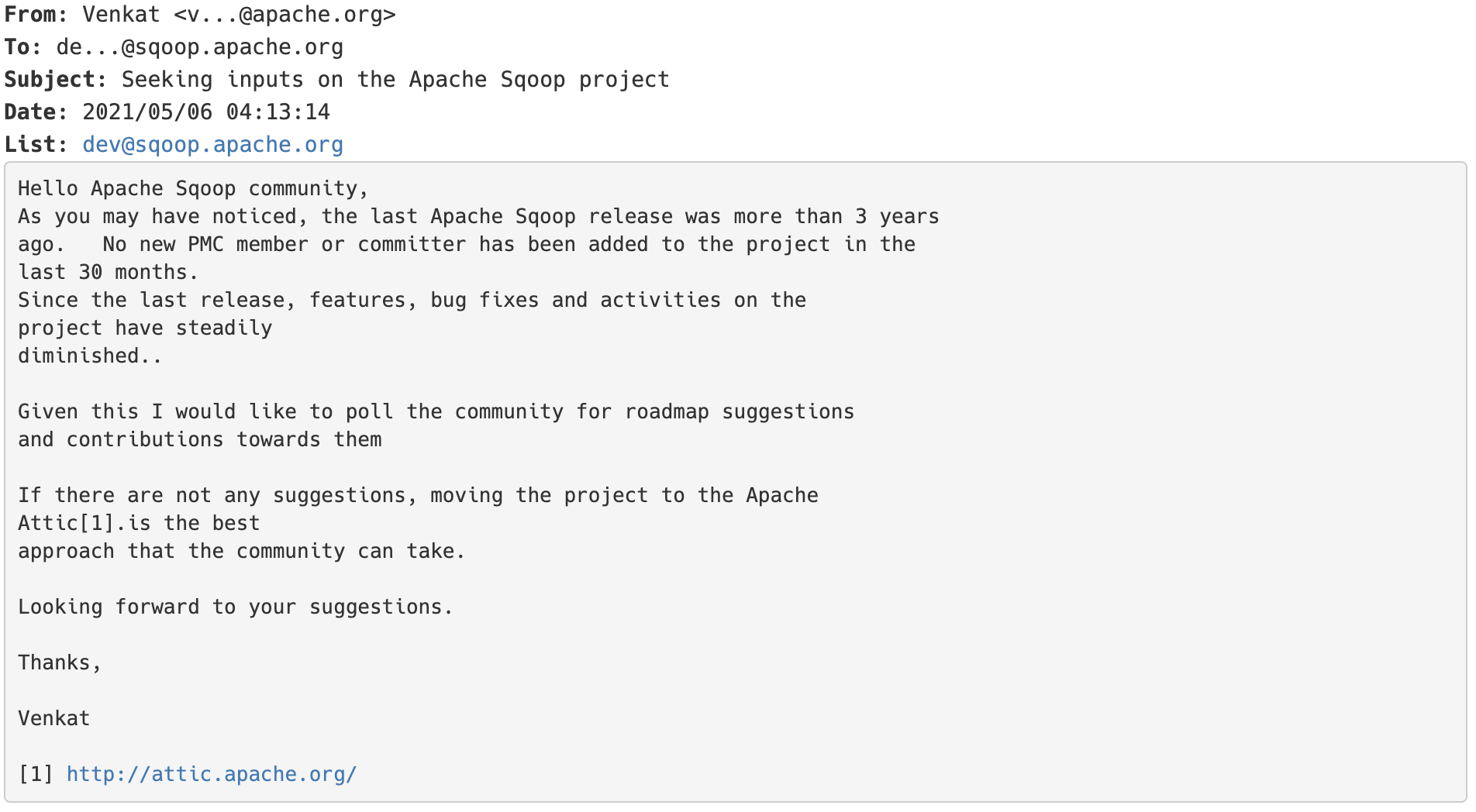
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 746℃ 0评论2喜欢
第二期上海大数据流处理(Shanghai Big Data Streaming 2nd Meetup)于2015年12月6日下午12:45在上海世贸大厦22层英特尔(中国)有限公司延安西路2299号进行,分享的主题如下:一、演讲者1/Speaker 1: 张天伦 英特尔大数据组软件工程师 个人介绍/BIO: 英特尔开源流处理系统Gearpump开发者,长期关注大数据领域和分布式计算,专注于流处理 w397090770 9年前 (2015-12-16) 3671℃ 0评论5喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4730℃ 0评论5喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 7年前 (2017-06-02) 199℃ 0评论0喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 3年前 (2022-03-29) 778℃ 0评论2喜欢
Apache Spark Delta Lake 的更新(update)和删除都是在 0.3.0 版本发布的,参见这里,对应的 Patch 参见这里。和前面几篇源码分析文章一样,我们也是先来看看在 Delta Lake 里面如何使用更新这个功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopDelta Lake 更新使用Delta Lake 的官方文档为我们提供如何 w397090770 5年前 (2019-10-19) 2047℃ 0评论3喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art w397090770 7年前 (2017-05-04) 1646℃ 0评论6喜欢
[caption id="attachment_751" align="aligncenter" width="536"] Guava学习之SetMultimap[/caption] SetMultimap及其子类的继承图如上所示。 SetMultimap是一个接口,继承自Multimap接口,同昨天说的ListMultimap接口类似,它也定义了所有继实现自SetMultimap的子类定义了一些共有的方法签名。SetMultimap接口并没有定义自己特有的方法签名,里面所 w397090770 11年前 (2013-09-25) 9208℃ 1评论4喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-22) 19202℃ 3评论14喜欢
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。实时数仓建设:实时数仓1.0 传统 w397090770 3年前 (2022-02-18) 737℃ 0评论2喜欢
本文作者:车好多大数据 OLAP 团队-王培,由车好多大数据 OLAP 团队相关同事投稿。Presto 简介简介Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。发展历史如下:2012年秋季,Facebook启动Presto项目2013年冬季,Presto开源 w397090770 4年前 (2020-12-21) 930℃ 0评论3喜欢
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略(这两种分区的代码解析可以参见:《Spark分区器HashPartitioner和RangePartitioner代码详解》),这两种分区策略在很多情况下都适合我们的场景。但是有些情况下,Spark内部不能符合咱们的需求,这时候我们就可以自定义分区策略。为此,Spark提供了相应的接口,我们只 w397090770 9年前 (2015-05-21) 18366℃ 0评论20喜欢
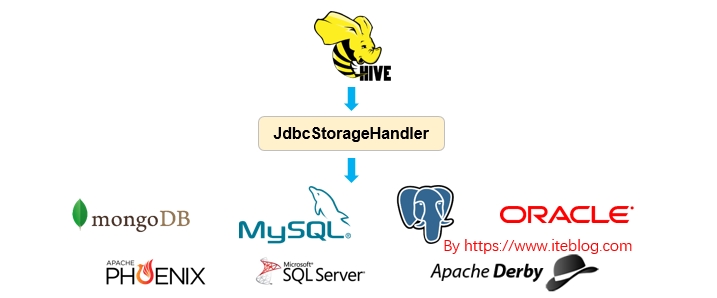
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 6年前 (2019-04-01) 3369℃ 0评论9喜欢
样本数据集 现在我们对于基本的东西已经有了一些认识,现在让我们尝试使用一些更加贴近现实的数据集。我准备了一些假想的客户银行账户信息的JSON文档样本。文档具有以下的模式(schema):[code lang="java"]{ "account_number": 0, "balance": 16623, "firstname": "Bradshaw", "lastname": &quo zz~~ 8年前 (2016-09-04) 1035℃ 0评论5喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列 w397090770 8年前 (2016-05-23) 22152℃ 0评论27喜欢